CPU優(yōu)化技術(shù)系列之NEON開(kāi)發(fā)設(shè)計(jì)實(shí)現(xiàn)方案
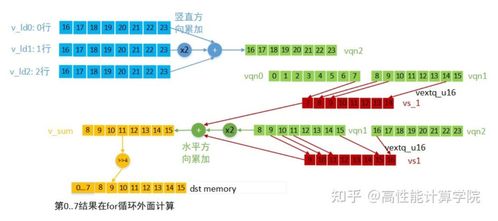
隨著移動(dòng)設(shè)備和嵌入式系統(tǒng)對(duì)高性能計(jì)算需求的不斷增長(zhǎng),ARM架構(gòu)下的NEON技術(shù)已成為提升CPU性能的關(guān)鍵手段。NEON作為ARM的高級(jí)SIMD(單指令多數(shù)據(jù))擴(kuò)展指令集,能夠顯著加速多媒體處理、信號(hào)處理、計(jì)算機(jī)視覺(jué)等數(shù)據(jù)密集型任務(wù)。本文將系統(tǒng)性地介紹NEON技術(shù)的開(kāi)發(fā)設(shè)計(jì)方案及實(shí)現(xiàn)路徑,為相關(guān)技術(shù)服務(wù)提供參考。
一、NEON技術(shù)概述
NEON是ARM Cortex-A系列處理器中的并行處理技術(shù),支持同時(shí)處理多個(gè)數(shù)據(jù)元素,適用于向量運(yùn)算。其128位寬寄存器可同時(shí)操作多個(gè)8位、16位、32位或64位數(shù)據(jù),適用于圖像處理、音頻編解碼、機(jī)器學(xué)習(xí)推理等場(chǎng)景。通過(guò)合理利用NEON,開(kāi)發(fā)者可在不增加硬件成本的前提下,實(shí)現(xiàn)數(shù)倍的性能提升。
二、NEON開(kāi)發(fā)設(shè)計(jì)流程
- 需求分析:明確應(yīng)用場(chǎng)景的性能瓶頸,例如圖像濾波、矩陣乘法或FFT運(yùn)算。識(shí)別可并行化的數(shù)據(jù)操作,評(píng)估NEON的適用性。
- 算法優(yōu)化:將標(biāo)量算法轉(zhuǎn)化為向量化形式。設(shè)計(jì)數(shù)據(jù)布局以匹配N(xiāo)EON的加載/存儲(chǔ)模式,避免非對(duì)齊內(nèi)存訪問(wèn)。常用技巧包括循環(huán)展開(kāi)、數(shù)據(jù)重排和減少分支預(yù)測(cè)。
- 指令選擇:根據(jù)數(shù)據(jù)類(lèi)型(如int8、float32)選擇適當(dāng)?shù)腘EON指令。ARM提供內(nèi)在函數(shù)(intrinsics)和匯編兩種編程方式,內(nèi)在函數(shù)更易于維護(hù),而匯編可最大化性能。
- 性能調(diào)優(yōu):通過(guò)分析工具(如ARM DS-5或Linux perf)檢測(cè)緩存命中率和指令吞吐量,優(yōu)化內(nèi)存訪問(wèn)模式,減少流水線停頓。
三、實(shí)現(xiàn)方案與示例
以圖像灰度化為例,傳統(tǒng)逐像素處理效率較低,而NEON可并行處理多個(gè)像素。以下為使用ARM NEON內(nèi)在函數(shù)的簡(jiǎn)化代碼:`c
#include
void grayscaleneon(uint8t rgb, uint8_t gray, int len) {
int i;
for (i = 0; i < len; i += 16) {
uint8x16x3t rgbvec = vld3qu8(rgb + i * 3); // 加載16個(gè)像素的RGB數(shù)據(jù)
uint16x8t rlo = vmovlu8(vgetlowu8(rgbvec.val[0])); // 擴(kuò)展R通道
uint16x8t glo = vmovlu8(vgetlowu8(rgbvec.val[1])); // 擴(kuò)展G通道
uint16x8t blo = vmovlu8(vgetlowu8(rgbvec.val[2])); // 擴(kuò)展B通道
// 灰度公式:0.299*R + 0.587*G + 0.114*B
uint16x8t graylo = vaddqu16(vmulqnu16(rlo, 77),
vaddqu16(vmulqnu16(glo, 150),
vmulqnu16(blo, 29)));
graylo = vshrqnu16(graylo, 8); // 右移8位近似除法
vst1qu8(gray + i, vmovnu16(gray_lo)); // 存儲(chǔ)結(jié)果
}
}`
此實(shí)現(xiàn)通過(guò)一次處理16像素,顯著提升了吞吐量。實(shí)際應(yīng)用中需結(jié)合具體硬件調(diào)整并行度。
四、技術(shù)服務(wù)支持
為保障NEON開(kāi)發(fā)的順利實(shí)施,技術(shù)服務(wù)應(yīng)涵蓋以下方面:
- 架構(gòu)咨詢:根據(jù)目標(biāo)平臺(tái)(如Cortex-A53/A76)提供NEON兼容性評(píng)估和性能預(yù)期分析。
- 代碼移植:協(xié)助將現(xiàn)有標(biāo)量代碼遷移至NEON優(yōu)化版本,確保功能正確性和跨平臺(tái)兼容性。
- 性能 profiling:使用工具鏈進(jìn)行深度性能分析,識(shí)別瓶頸并優(yōu)化關(guān)鍵代碼段。
- 測(cè)試驗(yàn)證:通過(guò)單元測(cè)試和基準(zhǔn)測(cè)試確保優(yōu)化后代碼的準(zhǔn)確性與穩(wěn)定性,避免數(shù)值精度損失。
五、未來(lái)展望
隨著ARM架構(gòu)在服務(wù)器、邊緣計(jì)算等領(lǐng)域的普及,NEON技術(shù)將與AI加速器(如NPU)協(xié)同工作,形成異構(gòu)計(jì)算解決方案。開(kāi)發(fā)者需持續(xù)關(guān)注ARMv9等新架構(gòu)的SVE2指令集,以應(yīng)對(duì)更復(fù)雜的并行化需求。
NEON開(kāi)發(fā)是一項(xiàng)結(jié)合算法設(shè)計(jì)、硬件特性和工程實(shí)踐的綜合性工作。通過(guò)系統(tǒng)性的設(shè)計(jì)實(shí)現(xiàn)方案,結(jié)合專業(yè)的技術(shù)服務(wù),可充分發(fā)揮ARM處理器的潛力,為應(yīng)用帶來(lái)顯著的性能提升。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.gx14.cn/product/14.html
更新時(shí)間:2026-04-08 23:03:48









